AWS Cloud Outage
AWS Cloud Outage
What does the AWS outage mean for cloud users?
What does the AWS outage mean for cloud users?
Author: Jacob Boyce
Author: Jacob Boyce
Posted: 25-11-2025
Posted: 25-11-2025
Every few years, the internet gets a reminder that even the most reliable cloud platforms in the world can have bad days.
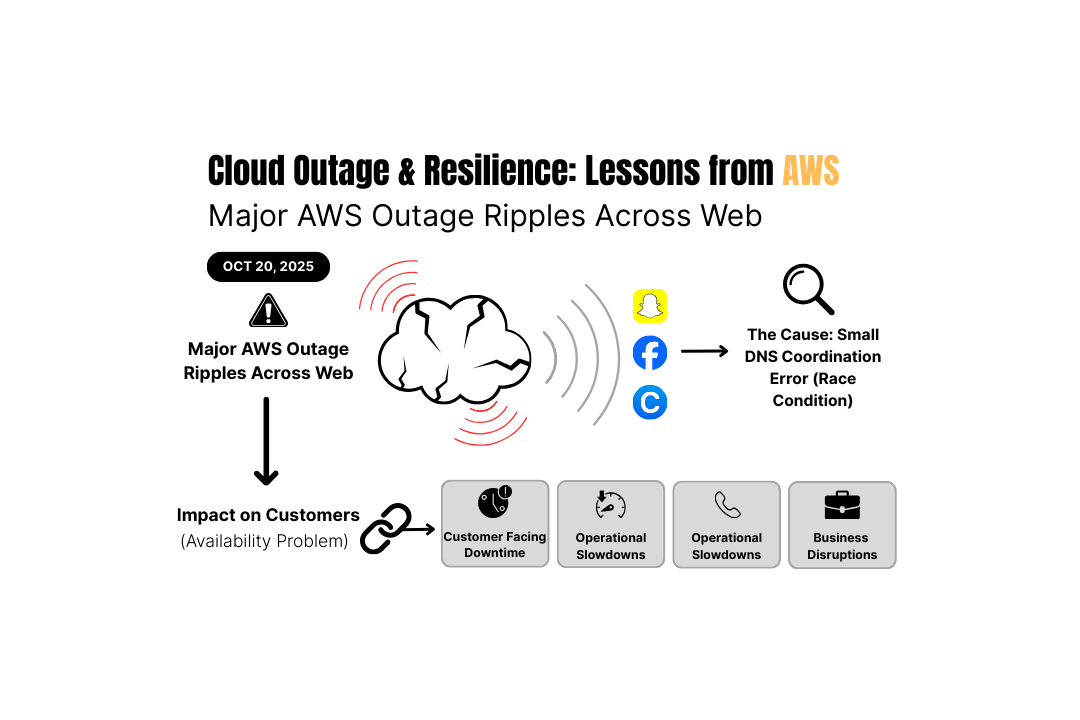
On the 20th of October, the backbone of a huge portion of the modern web suffered a major outage that rippled across industries. Snapchat, Fortnite, Facebook, Coinbase, Delta Airlines, United Airlines and dozens of other critical applications were disrupted.
🔍 The cause?
A surprisingly small DNS coordination error deep inside AWS’s infrastructure. One subtle race condition was enough to cascade into widespread service degradation across the platform.
📉 What this means for customers?
For customers running on AWS, this incident was ultimately an availability problem. If your application, API, or internal systems relied on AWS load balancers, EC2, authentication, or anything upstream of those services, then you likely saw errors, even though your code hadn’t changed at all.
Outages like this create several immediate impacts, Customer-facing downtime, Operational slowdowns, Support pressure, Business disruption.
But it’s also important to zoom out:
AWS still delivers availability numbers that are extraordinarily high, often five nines (99.999%) for core services. That’s significantly more reliable than most on-prem setups. And in practice, the majority of downtime that companies experience doesn’t come from the cloud provider at all, but from:
application bugs
misconfigured deployments
database migrations
dependency failures
cascading issues inside the product itself
So, while this outage was disruptive, it doesn’t change the broader reality: the cloud remains one of the most reliable infrastructure options available.
🛠️ What can we do about this?
Mitigating this specific failure, a deep DNS race condition inside AWS’s internal systems, is extremely difficult for most organizations. Avoiding it outright would require either a multi-cloud active architecture, or a fully independent on-prem + cloud failover paths. Both options come with steep costs, significant operational overhead, and their own availability challenges. For most businesses, they introduce more complexity than they solve. Teams can still significantly reduce the impact of outages by strengthening their own architecture:
Design for graceful degradation: Use caching, fallbacks, circuit breakers, and partial-feature modes so the whole app doesn’t fail when one dependency does.
Strengthen application reliability: Most outages come from our own code, invest in safe deployments, observability, and robust migration/testing practices.
Check your dependencies carefully: Map the services your system relies on (sometimes unintentionally) so a hidden upstream failure doesn’t become a complete outage.
Improve cloud resiliency: Use multiple availability zones, regional failover, redundancy, and autoscaling to reduce single-region or single-node exposure.
Test “bad day” scenarios: Run failover drills, rehearse incident response, and simulate degraded-mode behavior, teams recover faster when they’ve practiced.
Even the best cloud platforms aren’t immune to rare, complex failures. However, the best we can do here is analyse and learn from this to build stronger architectures.


